Databricks
DataHub supports integration with Databricks ecosystem using a multitude of connectors, depending on your exact setup.
Databricks Unity Catalog (new)
The recently introduced Unity Catalog provides a new way to govern your assets within the Databricks lakehouse. If you have Unity Catalog Enabled Workspace, you can use the unity-catalog source (aka databricks source, see below for details) to integrate your metadata into DataHub as an alternate to the Hive pathway. This also ingests hive metastore catalog in Databricks and is recommended approach to ingest Databricks ecosystem in DataHub.
Databricks Hive (old)
The alternative way to integrate is via the Hive connector. The Hive starter recipe has a section describing how to connect to your Databricks workspace.
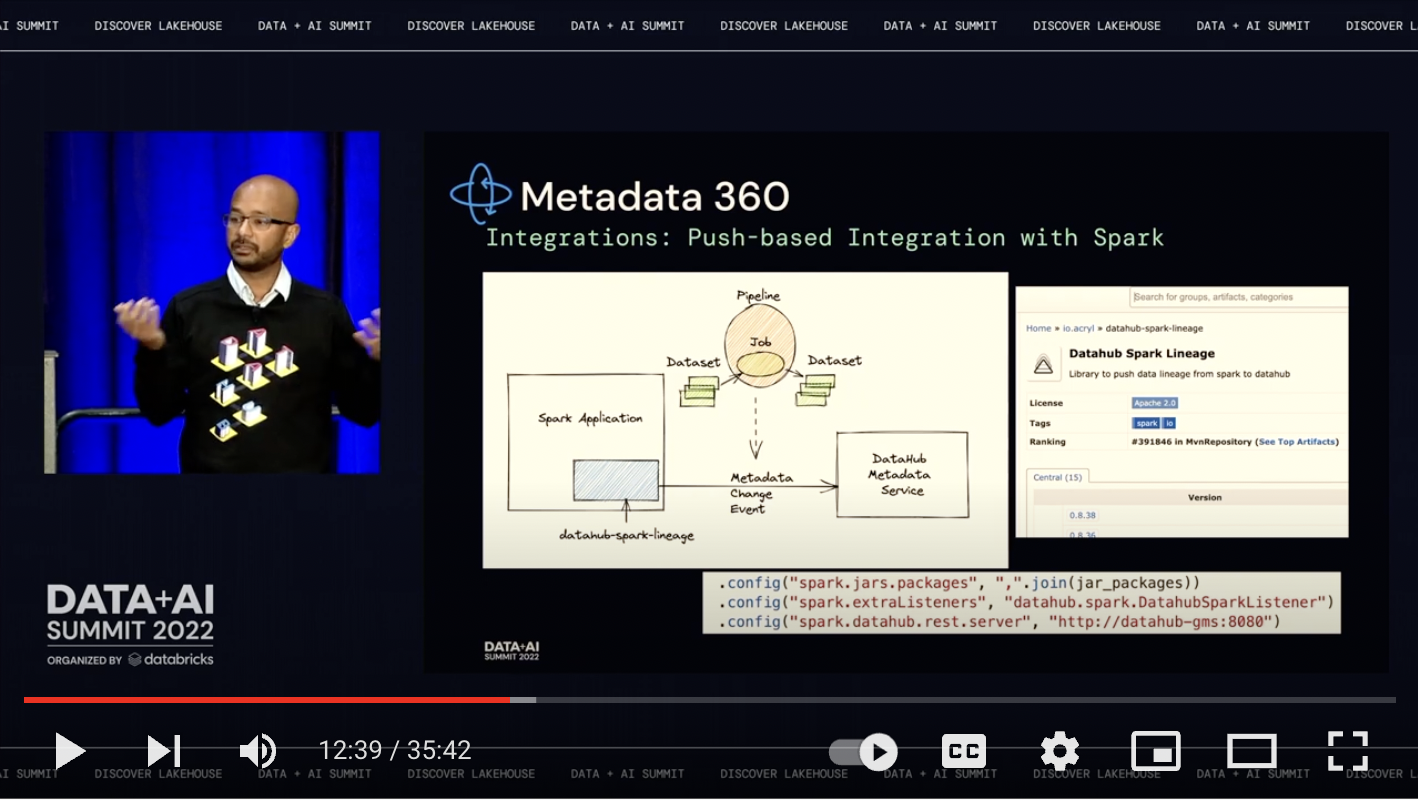
Databricks Spark
To complete the picture, we recommend adding push-based ingestion from your Spark jobs to see real-time activity and lineage between your Databricks tables and your Spark jobs. Use the Spark agent to push metadata to DataHub using the instructions here.
Watch the DataHub Talk at the Data and AI Summit 2022
For a deeper look at how to think about DataHub within and across your Databricks ecosystem, watch the recording of our talk at the Data and AI Summit 2022.
Important Capabilities
| Capability | Status | Notes |
|---|---|---|
| Asset Containers | ✅ | Enabled by default |
| Column-level Lineage | ✅ | Enabled by default |
| Dataset Usage | ✅ | Enabled by default |
| Descriptions | ✅ | Enabled by default |
| Detect Deleted Entities | ✅ | Optionally enabled via stateful_ingestion.remove_stale_metadata |
| Domains | ✅ | Supported via the domain config field |
| Extract Ownership | ✅ | Supported via the include_ownership config |
| Platform Instance | ✅ | Enabled by default |
| Schema Metadata | ✅ | Enabled by default |
| Table-Level Lineage | ✅ | Enabled by default |
This plugin extracts the following metadata from Databricks Unity Catalog:
- metastores
- schemas
- tables and column lineage
Prerequisities
- Get your Databricks instance's workspace url
- Create a Databricks Service Principal
- You can skip this step and use your own account to get things running quickly, but we strongly recommend creating a dedicated service principal for production use.
- Generate a Databricks Personal Access token following the following guides:
- Provision your service account:
- To ingest your workspace's metadata and lineage, your service principal must have all of the following:
- One of: metastore admin role, ownership of, or
USE CATALOGprivilege on any catalogs you want to ingest - One of: metastore admin role, ownership of, or
USE SCHEMAprivilege on any schemas you want to ingest - Ownership of or
SELECTprivilege on any tables and views you want to ingest - Ownership documentation
- Privileges documentation
- One of: metastore admin role, ownership of, or
- To ingest legacy hive_metastore catalog (
include_hive_metastore- enabled by default), your service principal must have all of the following:READ_METADATAandUSAGEprivilege onhive_metastorecatalogREAD_METADATAandUSAGEprivilege on schemas you want to ingestREAD_METADATAandUSAGEprivilege on tables and views you want to ingest- Hive Metastore Privileges documentation
- To ingest your workspace's notebooks and respective lineage, your service principal must have
CAN_READprivileges on the folders containing the notebooks you want to ingest: guide. - To
include_usage_statistics(enabled by default), your service principal must haveCAN_MANAGEpermissions on any SQL Warehouses you want to ingest: guide. - To ingest
profilinginformation withmethod: ge, you needSELECTprivileges on all profiled tables. - To ingest
profilinginformation withmethod: analyzeandcall_analyze: true(enabled by default), your service principal must have ownership orMODIFYprivilege on any tables you want to profile.- Alternatively, you can run ANALYZE TABLE yourself on any tables you want to profile, then set
call_analyzetofalse. You will still needSELECTprivilege on those tables to fetch the results.
- Alternatively, you can run ANALYZE TABLE yourself on any tables you want to profile, then set
- To ingest your workspace's metadata and lineage, your service principal must have all of the following:
- Check the starter recipe below and replace
workspace_urlandtokenwith your information from the previous steps.
CLI based Ingestion
Install the Plugin
pip install 'acryl-datahub[unity-catalog]'
Starter Recipe
Check out the following recipe to get started with ingestion! See below for full configuration options.
For general pointers on writing and running a recipe, see our main recipe guide.
source:
type: unity-catalog
config:
workspace_url: https://my-workspace.cloud.databricks.com
token: "<token>"
include_metastore: false
include_ownership: true
profiling:
method: "ge"
enabled: true
warehouse_id: "<warehouse_id>"
profile_table_level_only: false
max_wait_secs: 60
pattern:
deny:
- ".*\\.unwanted_schema"
# emit_siblings: true
# delta_lake_options:
# platform_instance_name: null
# env: 'PROD'
# profiling:
# method: "analyze"
# enabled: true
# warehouse_id: "<warehouse_id>"
# profile_table_level_only: true
# call_analyze: true
# catalogs: ["my_catalog"]
# schema_pattern:
# deny:
# - information_schema
# table_pattern:
# allow:
# - my_catalog.my_schema.my_table
# First you have to create domains on Datahub by following this guide -> https://datahubproject.io/docs/domains/#domains-setup-prerequisites-and-permissions
# domain:
# urn:li:domain:1111-222-333-444-555:
# allow:
# - main.*
stateful_ingestion:
enabled: true
pipeline_name: acme-corp-unity
# sink configs if needed
Config Details
- Options
- Schema
Note that a . is used to denote nested fields in the YAML recipe.
| Field | Description |
|---|---|
token ✅ string | Databricks personal access token |
workspace_url ✅ string | Databricks workspace url. e.g. https://my-workspace.cloud.databricks.com |
bucket_duration Enum | Size of the time window to aggregate usage stats. Default: DAY |
column_lineage_column_limit integer | Limit the number of columns to get column level lineage. Default: 300 |
convert_urns_to_lowercase boolean | Whether to convert dataset urns to lowercase. Default: False |
emit_siblings boolean | Whether to emit siblings relation with corresponding delta-lake platform's table. If enabled, this will also ingest the corresponding delta-lake table. Default: True |
enable_stateful_profiling boolean | Enable stateful profiling. This will store profiling timestamps per dataset after successful profiling. and will not run profiling again in subsequent run if table has not been updated. Default: True |
end_time string(date-time) | Latest date of lineage/usage to consider. Default: Current time in UTC |
format_sql_queries boolean | Whether to format sql queries Default: False |
include_column_lineage boolean | Option to enable/disable lineage generation. Currently we have to call a rest call per column to get column level lineage due to the Databrick api which can slow down ingestion. Default: True |
include_external_lineage boolean | Option to enable/disable lineage generation for external tables. Only external S3 tables are supported at the moment. Default: True |
include_hive_metastore boolean | Whether to ingest legacy hive_metastore catalog. This requires executing queries on SQL warehouse. Default: True |
include_metastore boolean | Whether to ingest the workspace's metastore as a container and include it in all urns. Changing this will affect the urns of all entities in the workspace. This config is deprecated and will be removed in the future, so it is recommended to not set this to True for new ingestions. If you have an existing unity catalog ingestion, you'll want to avoid duplicates by soft deleting existing data. If stateful ingestion is enabled, running with include_metastore: false should be sufficient. Otherwise, we recommend deleting via the cli: datahub delete --platform databricks and re-ingesting with include_metastore: false. Default: False |
include_notebooks boolean | Ingest notebooks, represented as DataHub datasets. Default: False |
include_operational_stats boolean | Whether to display operational stats. Default: True |
include_ownership boolean | Option to enable/disable ownership generation for metastores, catalogs, schemas, and tables. Default: False |
include_read_operational_stats boolean | Whether to report read operational stats. Experimental. Default: False |
include_table_lineage boolean | Option to enable/disable lineage generation. Default: True |
include_table_location_lineage boolean | If the source supports it, include table lineage to the underlying storage location. Default: True |
include_tables boolean | Whether tables should be ingested. Default: True |
include_top_n_queries boolean | Whether to ingest the top_n_queries. Default: True |
include_usage_statistics boolean | Generate usage statistics. Default: True |
include_view_column_lineage boolean | Populates column-level lineage for view->view and table->view lineage using DataHub's sql parser. Requires include_view_lineage to be enabled. Default: True |
include_view_lineage boolean | Populates view->view and table->view lineage using DataHub's sql parser. Default: True |
include_views boolean | Whether views should be ingested. Default: True |
incremental_lineage boolean | When enabled, emits lineage as incremental to existing lineage already in DataHub. When disabled, re-states lineage on each run. Default: False |
ingest_data_platform_instance_aspect boolean | Option to enable/disable ingestion of the data platform instance aspect. The default data platform instance id for a dataset is workspace_name Default: False |
options object | Any options specified here will be passed to SQLAlchemy.create_engine as kwargs. |
platform_instance string | The instance of the platform that all assets produced by this recipe belong to |
scheme string | Default: databricks |
start_time string(date-time) | Earliest date of lineage/usage to consider. Default: Last full day in UTC (or hour, depending on bucket_duration). You can also specify relative time with respect to end_time such as '-7 days' Or '-7d'. |
top_n_queries integer | Number of top queries to save to each table. Default: 10 |
use_file_backed_cache boolean | Whether to use a file backed cache for the view definitions. Default: True |
warehouse_id string | SQL Warehouse id, for running queries. If not set, will use the default warehouse. |
workspace_name string | Name of the workspace. Default to deployment name present in workspace_url |
env string | The environment that all assets produced by this connector belong to Default: PROD |
catalog_pattern AllowDenyPattern | Regex patterns for catalogs to filter in ingestion. Specify regex to match the full metastore.catalog name. Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
catalog_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
catalog_pattern.allow array | List of regex patterns to include in ingestion Default: ['.*'] |
catalog_pattern.allow.string string | |
catalog_pattern.deny array | List of regex patterns to exclude from ingestion. Default: [] |
catalog_pattern.deny.string string | |
catalogs array | Fixed list of catalogs to ingest. If not specified, catalogs will be ingested based on catalog_pattern. |
catalogs.string string | |
classification ClassificationConfig | For details, refer Classification. Default: {'enabled': False, 'sample_size': 100, 'max_worker... |
classification.enabled boolean | Whether classification should be used to auto-detect glossary terms Default: False |
classification.info_type_to_term map(str,string) | |
classification.max_workers integer | Number of worker processes to use for classification. Set to 1 to disable. Default: 4 |
classification.sample_size integer | Number of sample values used for classification. Default: 100 |
classification.classifiers array | Classifiers to use to auto-detect glossary terms. If more than one classifier, infotype predictions from the classifier defined later in sequence take precedance. Default: [{'type': 'datahub', 'config': None}] |
classification.classifiers.DynamicTypedClassifierConfig DynamicTypedClassifierConfig | |
classification.classifiers.DynamicTypedClassifierConfig.type ❓ string | The type of the classifier to use. For DataHub, use datahub |
classification.classifiers.DynamicTypedClassifierConfig.config object | The configuration required for initializing the classifier. If not specified, uses defaults for classifer type. |
classification.column_pattern AllowDenyPattern | Regex patterns to filter columns for classification. This is used in combination with other patterns in parent config. Specify regex to match the column name in database.schema.table.column format. Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
classification.column_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
classification.column_pattern.allow array | List of regex patterns to include in ingestion Default: ['.*'] |
classification.column_pattern.allow.string string | |
classification.column_pattern.deny array | List of regex patterns to exclude from ingestion. Default: [] |
classification.column_pattern.deny.string string | |
classification.table_pattern AllowDenyPattern | Regex patterns to filter tables for classification. This is used in combination with other patterns in parent config. Specify regex to match the entire table name in database.schema.table format. e.g. to match all tables starting with customer in Customer database and public schema, use the regex 'Customer.public.customer.*' Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
classification.table_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
classification.table_pattern.allow array | List of regex patterns to include in ingestion Default: ['.*'] |
classification.table_pattern.allow.string string | |
classification.table_pattern.deny array | List of regex patterns to exclude from ingestion. Default: [] |
classification.table_pattern.deny.string string | |
delta_lake_options DeltaLakeDetails | Details about the delta lake, incase to emit siblings Default: {'platform_instance_name': None, 'env': 'PROD'} |
delta_lake_options.platform_instance_name string | Delta-lake paltform instance name |
delta_lake_options.env string | Delta-lake environment Default: PROD |
domain map(str,AllowDenyPattern) | A class to store allow deny regexes |
domain. key.allowarray | List of regex patterns to include in ingestion Default: ['.*'] |
domain. key.allow.stringstring | |
domain. key.ignoreCaseboolean | Whether to ignore case sensitivity during pattern matching. Default: True |
domain. key.denyarray | List of regex patterns to exclude from ingestion. Default: [] |
domain. key.deny.stringstring | |
notebook_pattern AllowDenyPattern | Regex patterns for notebooks to filter in ingestion, based on notebook path. Specify regex to match the entire notebook path in /<dir>/.../<name> format. e.g. to match all notebooks in the root Shared directory, use the regex /Shared/.*. Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
notebook_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
notebook_pattern.allow array | List of regex patterns to include in ingestion Default: ['.*'] |
notebook_pattern.allow.string string | |
notebook_pattern.deny array | List of regex patterns to exclude from ingestion. Default: [] |
notebook_pattern.deny.string string | |
profile_pattern AllowDenyPattern | Regex patterns to filter tables (or specific columns) for profiling during ingestion. Note that only tables allowed by the table_pattern will be considered. Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
profile_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
profile_pattern.allow array | List of regex patterns to include in ingestion Default: ['.*'] |
profile_pattern.allow.string string | |
profile_pattern.deny array | List of regex patterns to exclude from ingestion. Default: [] |
profile_pattern.deny.string string | |
schema_pattern AllowDenyPattern | Regex patterns for schemas to filter in ingestion. Specify regex to the full metastore.catalog.schema name. e.g. to match all tables in schema analytics, use the regex ^mymetastore\.mycatalog\.analytics$. Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
schema_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
schema_pattern.allow array | List of regex patterns to include in ingestion Default: ['.*'] |
schema_pattern.allow.string string | |
schema_pattern.deny array | List of regex patterns to exclude from ingestion. Default: [] |
schema_pattern.deny.string string | |
table_pattern AllowDenyPattern | Regex patterns for tables to filter in ingestion. Specify regex to match the entire table name in catalog.schema.table format. e.g. to match all tables starting with customer in Customer catalog and public schema, use the regex Customer\.public\.customer.*. Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
table_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
table_pattern.allow array | List of regex patterns to include in ingestion Default: ['.*'] |
table_pattern.allow.string string | |
table_pattern.deny array | List of regex patterns to exclude from ingestion. Default: [] |
table_pattern.deny.string string | |
user_email_pattern AllowDenyPattern | regex patterns for user emails to filter in usage. Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
user_email_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
user_email_pattern.allow array | List of regex patterns to include in ingestion Default: ['.*'] |
user_email_pattern.allow.string string | |
user_email_pattern.deny array | List of regex patterns to exclude from ingestion. Default: [] |
user_email_pattern.deny.string string | |
view_pattern AllowDenyPattern | Regex patterns for views to filter in ingestion. Note: Defaults to table_pattern if not specified. Specify regex to match the entire view name in database.schema.view format. e.g. to match all views starting with customer in Customer database and public schema, use the regex 'Customer.public.customer.*' Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
view_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
view_pattern.allow array | List of regex patterns to include in ingestion Default: ['.*'] |
view_pattern.allow.string string | |
view_pattern.deny array | List of regex patterns to exclude from ingestion. Default: [] |
view_pattern.deny.string string | |
profiling One of UnityCatalogGEProfilerConfig, UnityCatalogAnalyzeProfilerConfig | Data profiling configuration Default: {'enabled': False, 'operation_config': {'lower_fre... |
profiling.call_analyze boolean | Whether to call ANALYZE TABLE as part of profile ingestion.If false, will ingest the results of the most recent ANALYZE TABLE call, if any. Default: True |
profiling.catch_exceptions boolean | Default: True |
profiling.enabled boolean | Whether profiling should be done. Default: False |
profiling.field_sample_values_limit integer | Upper limit for number of sample values to collect for all columns. Default: 20 |
profiling.include_field_distinct_count boolean | Whether to profile for the number of distinct values for each column. Default: True |
profiling.include_field_distinct_value_frequencies boolean | Whether to profile for distinct value frequencies. Default: False |
profiling.include_field_histogram boolean | Whether to profile for the histogram for numeric fields. Default: False |
profiling.include_field_max_value boolean | Whether to profile for the max value of numeric columns. Default: True |
profiling.include_field_mean_value boolean | Whether to profile for the mean value of numeric columns. Default: True |
profiling.include_field_median_value boolean | Whether to profile for the median value of numeric columns. Default: True |
profiling.include_field_min_value boolean | Whether to profile for the min value of numeric columns. Default: True |
profiling.include_field_null_count boolean | Whether to profile for the number of nulls for each column. Default: True |
profiling.include_field_quantiles boolean | Whether to profile for the quantiles of numeric columns. Default: False |
profiling.include_field_sample_values boolean | Whether to profile for the sample values for all columns. Default: True |
profiling.include_field_stddev_value boolean | Whether to profile for the standard deviation of numeric columns. Default: True |
profiling.limit integer | Max number of documents to profile. By default, profiles all documents. |
profiling.max_number_of_fields_to_profile integer | A positive integer that specifies the maximum number of columns to profile for any table. None implies all columns. The cost of profiling goes up significantly as the number of columns to profile goes up. |
profiling.max_wait_secs integer | Maximum time to wait for a table to be profiled. |
profiling.max_workers integer | Number of worker threads to use for profiling. Set to 1 to disable. Default: 20 |
profiling.method Enum | One of: "ge" Default: ge |
profiling.offset integer | Offset in documents to profile. By default, uses no offset. |
profiling.partition_datetime string(date-time) | If specified, profile only the partition which matches this datetime. If not specified, profile the latest partition. Only Bigquery supports this. |
profiling.partition_profiling_enabled boolean | Whether to profile partitioned tables. Only BigQuery and Aws Athena supports this. If enabled, latest partition data is used for profiling. Default: True |
profiling.profile_external_tables boolean | Whether to profile external tables. Only Snowflake and Redshift supports this. Default: False |
profiling.profile_if_updated_since_days number | Profile table only if it has been updated since these many number of days. If set to null, no constraint of last modified time for tables to profile. Supported only in snowflake and BigQuery. |
profiling.profile_table_level_only boolean | Whether to perform profiling at table-level only, or include column-level profiling as well. Default: False |
profiling.profile_table_row_count_estimate_only boolean | Use an approximate query for row count. This will be much faster but slightly less accurate. Only supported for Postgres and MySQL. Default: False |
profiling.profile_table_row_limit integer | Profile tables only if their row count is less then specified count. If set to null, no limit on the row count of tables to profile. Supported only in snowflake and BigQuery Default: 5000000 |
profiling.profile_table_size_limit integer | Profile tables only if their size is less then specified GBs. If set to null, no limit on the size of tables to profile. Supported only in snowflake and BigQuery Default: 5 |
profiling.query_combiner_enabled boolean | This feature is still experimental and can be disabled if it causes issues. Reduces the total number of queries issued and speeds up profiling by dynamically combining SQL queries where possible. Default: True |
profiling.report_dropped_profiles boolean | Whether to report datasets or dataset columns which were not profiled. Set to True for debugging purposes. Default: False |
profiling.sample_size integer | Number of rows to be sampled from table for column level profiling.Applicable only if use_sampling is set to True. Default: 10000 |
profiling.turn_off_expensive_profiling_metrics boolean | Whether to turn off expensive profiling or not. This turns off profiling for quantiles, distinct_value_frequencies, histogram & sample_values. This also limits maximum number of fields being profiled to 10. Default: False |
profiling.use_sampling boolean | Whether to profile column level stats on sample of table. Only BigQuery and Snowflake support this. If enabled, profiling is done on rows sampled from table. Sampling is not done for smaller tables. Default: True |
profiling.warehouse_id string | SQL Warehouse id, for running profiling queries. |
profiling.operation_config One of OperationConfig, union(allOf), OperationConfig | Experimental feature. To specify operation configs. |
profiling.operation_config.lower_freq_profile_enabled boolean | Whether to do profiling at lower freq or not. This does not do any scheduling just adds additional checks to when not to run profiling. Default: False |
profiling.operation_config.profile_date_of_month integer | Number between 1 to 31 for date of month (both inclusive). If not specified, defaults to Nothing and this field does not take affect. |
profiling.operation_config.profile_day_of_week integer | Number between 0 to 6 for day of week (both inclusive). 0 is Monday and 6 is Sunday. If not specified, defaults to Nothing and this field does not take affect. |
profiling.pattern One of AllowDenyPattern, union(allOf), AllowDenyPattern | Regex patterns to filter tables for profiling during ingestion. Specify regex to match the catalog.schema.table format. Note that only tables allowed by the table_pattern will be considered. Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
profiling.pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
profiling.pattern.allow array | List of regex patterns to include in ingestion Default: ['.*'] |
profiling.pattern.allow.string string | |
profiling.pattern.deny array | List of regex patterns to exclude from ingestion. Default: [] |
profiling.pattern.deny.string string | |
profiling.tags_to_ignore_sampling array | Fixed list of tags to ignore sampling. If not specified, tables will be sampled based on use_sampling. |
profiling.tags_to_ignore_sampling.string string | |
stateful_ingestion StatefulStaleMetadataRemovalConfig | Unity Catalog Stateful Ingestion Config. |
stateful_ingestion.enabled boolean | Whether or not to enable stateful ingest. Default: True if a pipeline_name is set and either a datahub-rest sink or datahub_api is specified, otherwise False Default: False |
stateful_ingestion.remove_stale_metadata boolean | Soft-deletes the entities present in the last successful run but missing in the current run with stateful_ingestion enabled. Default: True |
The JSONSchema for this configuration is inlined below.
{
"title": "UnityCatalogSourceConfig",
"description": "Base configuration class for stateful ingestion for source configs to inherit from.",
"type": "object",
"properties": {
"convert_urns_to_lowercase": {
"title": "Convert Urns To Lowercase",
"description": "Whether to convert dataset urns to lowercase.",
"default": false,
"type": "boolean"
},
"enable_stateful_profiling": {
"title": "Enable Stateful Profiling",
"description": "Enable stateful profiling. This will store profiling timestamps per dataset after successful profiling. and will not run profiling again in subsequent run if table has not been updated. ",
"default": true,
"type": "boolean"
},
"env": {
"title": "Env",
"description": "The environment that all assets produced by this connector belong to",
"default": "PROD",
"type": "string"
},
"platform_instance": {
"title": "Platform Instance",
"description": "The instance of the platform that all assets produced by this recipe belong to",
"type": "string"
},
"bucket_duration": {
"description": "Size of the time window to aggregate usage stats.",
"default": "DAY",
"allOf": [
{
"$ref": "#/definitions/BucketDuration"
}
]
},
"end_time": {
"title": "End Time",
"description": "Latest date of lineage/usage to consider. Default: Current time in UTC",
"type": "string",
"format": "date-time"
},
"start_time": {
"title": "Start Time",
"description": "Earliest date of lineage/usage to consider. Default: Last full day in UTC (or hour, depending on `bucket_duration`). You can also specify relative time with respect to end_time such as '-7 days' Or '-7d'.",
"type": "string",
"format": "date-time"
},
"top_n_queries": {
"title": "Top N Queries",
"description": "Number of top queries to save to each table.",
"default": 10,
"exclusiveMinimum": 0,
"type": "integer"
},
"user_email_pattern": {
"title": "User Email Pattern",
"description": "regex patterns for user emails to filter in usage.",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"include_operational_stats": {
"title": "Include Operational Stats",
"description": "Whether to display operational stats.",
"default": true,
"type": "boolean"
},
"include_read_operational_stats": {
"title": "Include Read Operational Stats",
"description": "Whether to report read operational stats. Experimental.",
"default": false,
"type": "boolean"
},
"format_sql_queries": {
"title": "Format Sql Queries",
"description": "Whether to format sql queries",
"default": false,
"type": "boolean"
},
"include_top_n_queries": {
"title": "Include Top N Queries",
"description": "Whether to ingest the top_n_queries.",
"default": true,
"type": "boolean"
},
"stateful_ingestion": {
"title": "Stateful Ingestion",
"description": "Unity Catalog Stateful Ingestion Config.",
"allOf": [
{
"$ref": "#/definitions/StatefulStaleMetadataRemovalConfig"
}
]
},
"schema_pattern": {
"title": "Schema Pattern",
"description": "Regex patterns for schemas to filter in ingestion. Specify regex to the full `metastore.catalog.schema` name. e.g. to match all tables in schema analytics, use the regex `^mymetastore\\.mycatalog\\.analytics$`.",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"table_pattern": {
"title": "Table Pattern",
"description": "Regex patterns for tables to filter in ingestion. Specify regex to match the entire table name in `catalog.schema.table` format. e.g. to match all tables starting with customer in Customer catalog and public schema, use the regex `Customer\\.public\\.customer.*`.",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"view_pattern": {
"title": "View Pattern",
"description": "Regex patterns for views to filter in ingestion. Note: Defaults to table_pattern if not specified. Specify regex to match the entire view name in database.schema.view format. e.g. to match all views starting with customer in Customer database and public schema, use the regex 'Customer.public.customer.*'",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"classification": {
"title": "Classification",
"description": "For details, refer [Classification](../../../../metadata-ingestion/docs/dev_guides/classification.md).",
"default": {
"enabled": false,
"sample_size": 100,
"max_workers": 4,
"table_pattern": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"column_pattern": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"info_type_to_term": {},
"classifiers": [
{
"type": "datahub",
"config": null
}
]
},
"allOf": [
{
"$ref": "#/definitions/ClassificationConfig"
}
]
},
"incremental_lineage": {
"title": "Incremental Lineage",
"description": "When enabled, emits lineage as incremental to existing lineage already in DataHub. When disabled, re-states lineage on each run.",
"default": false,
"type": "boolean"
},
"options": {
"title": "Options",
"description": "Any options specified here will be passed to [SQLAlchemy.create_engine](https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine) as kwargs.",
"type": "object"
},
"profile_pattern": {
"title": "Profile Pattern",
"description": "Regex patterns to filter tables (or specific columns) for profiling during ingestion. Note that only tables allowed by the `table_pattern` will be considered.",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"domain": {
"title": "Domain",
"description": "Attach domains to catalogs, schemas or tables during ingestion using regex patterns. Domain key can be a guid like *urn:li:domain:ec428203-ce86-4db3-985d-5a8ee6df32ba* or a string like \"Marketing\".) If you provide strings, then datahub will attempt to resolve this name to a guid, and will error out if this fails. There can be multiple domain keys specified.",
"default": {},
"type": "object",
"additionalProperties": {
"$ref": "#/definitions/AllowDenyPattern"
}
},
"include_views": {
"title": "Include Views",
"description": "Whether views should be ingested.",
"default": true,
"type": "boolean"
},
"include_tables": {
"title": "Include Tables",
"description": "Whether tables should be ingested.",
"default": true,
"type": "boolean"
},
"include_table_location_lineage": {
"title": "Include Table Location Lineage",
"description": "If the source supports it, include table lineage to the underlying storage location.",
"default": true,
"type": "boolean"
},
"include_view_lineage": {
"title": "Include View Lineage",
"description": "Populates view->view and table->view lineage using DataHub's sql parser.",
"default": true,
"type": "boolean"
},
"include_view_column_lineage": {
"title": "Include View Column Lineage",
"description": "Populates column-level lineage for view->view and table->view lineage using DataHub's sql parser. Requires `include_view_lineage` to be enabled.",
"default": true,
"type": "boolean"
},
"use_file_backed_cache": {
"title": "Use File Backed Cache",
"description": "Whether to use a file backed cache for the view definitions.",
"default": true,
"type": "boolean"
},
"profiling": {
"title": "Profiling",
"description": "Data profiling configuration",
"default": {
"enabled": false,
"operation_config": {
"lower_freq_profile_enabled": false,
"profile_day_of_week": null,
"profile_date_of_month": null
},
"limit": null,
"offset": null,
"report_dropped_profiles": false,
"turn_off_expensive_profiling_metrics": false,
"profile_table_level_only": false,
"include_field_null_count": true,
"include_field_distinct_count": true,
"include_field_min_value": true,
"include_field_max_value": true,
"include_field_mean_value": true,
"include_field_median_value": true,
"include_field_stddev_value": true,
"include_field_quantiles": false,
"include_field_distinct_value_frequencies": false,
"include_field_histogram": false,
"include_field_sample_values": true,
"field_sample_values_limit": 20,
"max_number_of_fields_to_profile": null,
"profile_if_updated_since_days": null,
"profile_table_size_limit": 5,
"profile_table_row_limit": 5000000,
"profile_table_row_count_estimate_only": false,
"max_workers": 20,
"query_combiner_enabled": true,
"catch_exceptions": true,
"partition_profiling_enabled": true,
"partition_datetime": null,
"use_sampling": true,
"sample_size": 10000,
"profile_external_tables": false,
"tags_to_ignore_sampling": null,
"method": "ge",
"warehouse_id": null,
"pattern": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"max_wait_secs": null
},
"discriminator": {
"propertyName": "method",
"mapping": {
"ge": "#/definitions/UnityCatalogGEProfilerConfig",
"analyze": "#/definitions/UnityCatalogAnalyzeProfilerConfig"
}
},
"oneOf": [
{
"$ref": "#/definitions/UnityCatalogGEProfilerConfig"
},
{
"$ref": "#/definitions/UnityCatalogAnalyzeProfilerConfig"
}
]
},
"token": {
"title": "Token",
"description": "Databricks personal access token",
"type": "string"
},
"workspace_url": {
"title": "Workspace Url",
"description": "Databricks workspace url. e.g. https://my-workspace.cloud.databricks.com",
"type": "string"
},
"warehouse_id": {
"title": "Warehouse Id",
"description": "SQL Warehouse id, for running queries. If not set, will use the default warehouse.",
"type": "string"
},
"include_hive_metastore": {
"title": "Include Hive Metastore",
"description": "Whether to ingest legacy `hive_metastore` catalog. This requires executing queries on SQL warehouse.",
"default": true,
"type": "boolean"
},
"workspace_name": {
"title": "Workspace Name",
"description": "Name of the workspace. Default to deployment name present in workspace_url",
"type": "string"
},
"include_metastore": {
"title": "Include Metastore",
"description": "Whether to ingest the workspace's metastore as a container and include it in all urns. Changing this will affect the urns of all entities in the workspace. This config is deprecated and will be removed in the future, so it is recommended to not set this to `True` for new ingestions. If you have an existing unity catalog ingestion, you'll want to avoid duplicates by soft deleting existing data. If stateful ingestion is enabled, running with `include_metastore: false` should be sufficient. Otherwise, we recommend deleting via the cli: `datahub delete --platform databricks` and re-ingesting with `include_metastore: false`.",
"default": false,
"type": "boolean"
},
"ingest_data_platform_instance_aspect": {
"title": "Ingest Data Platform Instance Aspect",
"description": "Option to enable/disable ingestion of the data platform instance aspect. The default data platform instance id for a dataset is workspace_name",
"default": false,
"type": "boolean"
},
"catalogs": {
"title": "Catalogs",
"description": "Fixed list of catalogs to ingest. If not specified, catalogs will be ingested based on `catalog_pattern`.",
"type": "array",
"items": {
"type": "string"
}
},
"catalog_pattern": {
"title": "Catalog Pattern",
"description": "Regex patterns for catalogs to filter in ingestion. Specify regex to match the full `metastore.catalog` name.",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"notebook_pattern": {
"title": "Notebook Pattern",
"description": "Regex patterns for notebooks to filter in ingestion, based on notebook *path*. Specify regex to match the entire notebook path in `/<dir>/.../<name>` format. e.g. to match all notebooks in the root Shared directory, use the regex `/Shared/.*`.",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"include_table_lineage": {
"title": "Include Table Lineage",
"description": "Option to enable/disable lineage generation.",
"default": true,
"type": "boolean"
},
"include_external_lineage": {
"title": "Include External Lineage",
"description": "Option to enable/disable lineage generation for external tables. Only external S3 tables are supported at the moment.",
"default": true,
"type": "boolean"
},
"include_notebooks": {
"title": "Include Notebooks",
"description": "Ingest notebooks, represented as DataHub datasets.",
"default": false,
"type": "boolean"
},
"include_ownership": {
"title": "Include Ownership",
"description": "Option to enable/disable ownership generation for metastores, catalogs, schemas, and tables.",
"default": false,
"type": "boolean"
},
"include_column_lineage": {
"title": "Include Column Lineage",
"description": "Option to enable/disable lineage generation. Currently we have to call a rest call per column to get column level lineage due to the Databrick api which can slow down ingestion. ",
"default": true,
"type": "boolean"
},
"column_lineage_column_limit": {
"title": "Column Lineage Column Limit",
"description": "Limit the number of columns to get column level lineage. ",
"default": 300,
"type": "integer"
},
"include_usage_statistics": {
"title": "Include Usage Statistics",
"description": "Generate usage statistics.",
"default": true,
"type": "boolean"
},
"emit_siblings": {
"title": "Emit Siblings",
"description": "Whether to emit siblings relation with corresponding delta-lake platform's table. If enabled, this will also ingest the corresponding delta-lake table.",
"default": true,
"type": "boolean"
},
"delta_lake_options": {
"title": "Delta Lake Options",
"description": "Details about the delta lake, incase to emit siblings",
"default": {
"platform_instance_name": null,
"env": "PROD"
},
"allOf": [
{
"$ref": "#/definitions/DeltaLakeDetails"
}
]
},
"scheme": {
"title": "Scheme",
"default": "databricks",
"type": "string"
}
},
"required": [
"token",
"workspace_url"
],
"additionalProperties": false,
"definitions": {
"BucketDuration": {
"title": "BucketDuration",
"description": "An enumeration.",
"enum": [
"DAY",
"HOUR"
],
"type": "string"
},
"AllowDenyPattern": {
"title": "AllowDenyPattern",
"description": "A class to store allow deny regexes",
"type": "object",
"properties": {
"allow": {
"title": "Allow",
"description": "List of regex patterns to include in ingestion",
"default": [
".*"
],
"type": "array",
"items": {
"type": "string"
}
},
"deny": {
"title": "Deny",
"description": "List of regex patterns to exclude from ingestion.",
"default": [],
"type": "array",
"items": {
"type": "string"
}
},
"ignoreCase": {
"title": "Ignorecase",
"description": "Whether to ignore case sensitivity during pattern matching.",
"default": true,
"type": "boolean"
}
},
"additionalProperties": false
},
"DynamicTypedStateProviderConfig": {
"title": "DynamicTypedStateProviderConfig",
"type": "object",
"properties": {
"type": {
"title": "Type",
"description": "The type of the state provider to use. For DataHub use `datahub`",
"type": "string"
},
"config": {
"title": "Config",
"description": "The configuration required for initializing the state provider. Default: The datahub_api config if set at pipeline level. Otherwise, the default DatahubClientConfig. See the defaults (https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/src/datahub/ingestion/graph/client.py#L19).",
"default": {},
"type": "object"
}
},
"required": [
"type"
],
"additionalProperties": false
},
"StatefulStaleMetadataRemovalConfig": {
"title": "StatefulStaleMetadataRemovalConfig",
"description": "Base specialized config for Stateful Ingestion with stale metadata removal capability.",
"type": "object",
"properties": {
"enabled": {
"title": "Enabled",
"description": "Whether or not to enable stateful ingest. Default: True if a pipeline_name is set and either a datahub-rest sink or `datahub_api` is specified, otherwise False",
"default": false,
"type": "boolean"
},
"remove_stale_metadata": {
"title": "Remove Stale Metadata",
"description": "Soft-deletes the entities present in the last successful run but missing in the current run with stateful_ingestion enabled.",
"default": true,
"type": "boolean"
}
},
"additionalProperties": false
},
"DynamicTypedClassifierConfig": {
"title": "DynamicTypedClassifierConfig",
"type": "object",
"properties": {
"type": {
"title": "Type",
"description": "The type of the classifier to use. For DataHub, use `datahub`",
"type": "string"
},
"config": {
"title": "Config",
"description": "The configuration required for initializing the classifier. If not specified, uses defaults for classifer type."
}
},
"required": [
"type"
],
"additionalProperties": false
},
"ClassificationConfig": {
"title": "ClassificationConfig",
"type": "object",
"properties": {
"enabled": {
"title": "Enabled",
"description": "Whether classification should be used to auto-detect glossary terms",
"default": false,
"type": "boolean"
},
"sample_size": {
"title": "Sample Size",
"description": "Number of sample values used for classification.",
"default": 100,
"type": "integer"
},
"max_workers": {
"title": "Max Workers",
"description": "Number of worker processes to use for classification. Set to 1 to disable.",
"default": 4,
"type": "integer"
},
"table_pattern": {
"title": "Table Pattern",
"description": "Regex patterns to filter tables for classification. This is used in combination with other patterns in parent config. Specify regex to match the entire table name in `database.schema.table` format. e.g. to match all tables starting with customer in Customer database and public schema, use the regex 'Customer.public.customer.*'",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"column_pattern": {
"title": "Column Pattern",
"description": "Regex patterns to filter columns for classification. This is used in combination with other patterns in parent config. Specify regex to match the column name in `database.schema.table.column` format.",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"info_type_to_term": {
"title": "Info Type To Term",
"description": "Optional mapping to provide glossary term identifier for info type",
"default": {},
"type": "object",
"additionalProperties": {
"type": "string"
}
},
"classifiers": {
"title": "Classifiers",
"description": "Classifiers to use to auto-detect glossary terms. If more than one classifier, infotype predictions from the classifier defined later in sequence take precedance.",
"default": [
{
"type": "datahub",
"config": null
}
],
"type": "array",
"items": {
"$ref": "#/definitions/DynamicTypedClassifierConfig"
}
}
},
"additionalProperties": false
},
"OperationConfig": {
"title": "OperationConfig",
"type": "object",
"properties": {
"lower_freq_profile_enabled": {
"title": "Lower Freq Profile Enabled",
"description": "Whether to do profiling at lower freq or not. This does not do any scheduling just adds additional checks to when not to run profiling.",
"default": false,
"type": "boolean"
},
"profile_day_of_week": {
"title": "Profile Day Of Week",
"description": "Number between 0 to 6 for day of week (both inclusive). 0 is Monday and 6 is Sunday. If not specified, defaults to Nothing and this field does not take affect.",
"type": "integer"
},
"profile_date_of_month": {
"title": "Profile Date Of Month",
"description": "Number between 1 to 31 for date of month (both inclusive). If not specified, defaults to Nothing and this field does not take affect.",
"type": "integer"
}
},
"additionalProperties": false
},
"UnityCatalogGEProfilerConfig": {
"title": "UnityCatalogGEProfilerConfig",
"type": "object",
"properties": {
"enabled": {
"title": "Enabled",
"description": "Whether profiling should be done.",
"default": false,
"type": "boolean"
},
"operation_config": {
"title": "Operation Config",
"description": "Experimental feature. To specify operation configs.",
"allOf": [
{
"$ref": "#/definitions/OperationConfig"
}
]
},
"limit": {
"title": "Limit",
"description": "Max number of documents to profile. By default, profiles all documents.",
"type": "integer"
},
"offset": {
"title": "Offset",
"description": "Offset in documents to profile. By default, uses no offset.",
"type": "integer"
},
"report_dropped_profiles": {
"title": "Report Dropped Profiles",
"description": "Whether to report datasets or dataset columns which were not profiled. Set to `True` for debugging purposes.",
"default": false,
"type": "boolean"
},
"turn_off_expensive_profiling_metrics": {
"title": "Turn Off Expensive Profiling Metrics",
"description": "Whether to turn off expensive profiling or not. This turns off profiling for quantiles, distinct_value_frequencies, histogram & sample_values. This also limits maximum number of fields being profiled to 10.",
"default": false,
"type": "boolean"
},
"profile_table_level_only": {
"title": "Profile Table Level Only",
"description": "Whether to perform profiling at table-level only, or include column-level profiling as well.",
"default": false,
"type": "boolean"
},
"include_field_null_count": {
"title": "Include Field Null Count",
"description": "Whether to profile for the number of nulls for each column.",
"default": true,
"type": "boolean"
},
"include_field_distinct_count": {
"title": "Include Field Distinct Count",
"description": "Whether to profile for the number of distinct values for each column.",
"default": true,
"type": "boolean"
},
"include_field_min_value": {
"title": "Include Field Min Value",
"description": "Whether to profile for the min value of numeric columns.",
"default": true,
"type": "boolean"
},
"include_field_max_value": {
"title": "Include Field Max Value",
"description": "Whether to profile for the max value of numeric columns.",
"default": true,
"type": "boolean"
},
"include_field_mean_value": {
"title": "Include Field Mean Value",
"description": "Whether to profile for the mean value of numeric columns.",
"default": true,
"type": "boolean"
},
"include_field_median_value": {
"title": "Include Field Median Value",
"description": "Whether to profile for the median value of numeric columns.",
"default": true,
"type": "boolean"
},
"include_field_stddev_value": {
"title": "Include Field Stddev Value",
"description": "Whether to profile for the standard deviation of numeric columns.",
"default": true,
"type": "boolean"
},
"include_field_quantiles": {
"title": "Include Field Quantiles",
"description": "Whether to profile for the quantiles of numeric columns.",
"default": false,
"type": "boolean"
},
"include_field_distinct_value_frequencies": {
"title": "Include Field Distinct Value Frequencies",
"description": "Whether to profile for distinct value frequencies.",
"default": false,
"type": "boolean"
},
"include_field_histogram": {
"title": "Include Field Histogram",
"description": "Whether to profile for the histogram for numeric fields.",
"default": false,
"type": "boolean"
},
"include_field_sample_values": {
"title": "Include Field Sample Values",
"description": "Whether to profile for the sample values for all columns.",
"default": true,
"type": "boolean"
},
"field_sample_values_limit": {
"title": "Field Sample Values Limit",
"description": "Upper limit for number of sample values to collect for all columns.",
"default": 20,
"type": "integer"
},
"max_number_of_fields_to_profile": {
"title": "Max Number Of Fields To Profile",
"description": "A positive integer that specifies the maximum number of columns to profile for any table. `None` implies all columns. The cost of profiling goes up significantly as the number of columns to profile goes up.",
"exclusiveMinimum": 0,
"type": "integer"
},
"profile_if_updated_since_days": {
"title": "Profile If Updated Since Days",
"description": "Profile table only if it has been updated since these many number of days. If set to `null`, no constraint of last modified time for tables to profile. Supported only in `snowflake` and `BigQuery`.",
"exclusiveMinimum": 0,
"type": "number"
},
"profile_table_size_limit": {
"title": "Profile Table Size Limit",
"description": "Profile tables only if their size is less then specified GBs. If set to `null`, no limit on the size of tables to profile. Supported only in `snowflake` and `BigQuery`",
"default": 5,
"type": "integer"
},
"profile_table_row_limit": {
"title": "Profile Table Row Limit",
"description": "Profile tables only if their row count is less then specified count. If set to `null`, no limit on the row count of tables to profile. Supported only in `snowflake` and `BigQuery`",
"default": 5000000,
"type": "integer"
},
"profile_table_row_count_estimate_only": {
"title": "Profile Table Row Count Estimate Only",
"description": "Use an approximate query for row count. This will be much faster but slightly less accurate. Only supported for Postgres and MySQL. ",
"default": false,
"type": "boolean"
},
"max_workers": {
"title": "Max Workers",
"description": "Number of worker threads to use for profiling. Set to 1 to disable.",
"default": 20,
"type": "integer"
},
"query_combiner_enabled": {
"title": "Query Combiner Enabled",
"description": "*This feature is still experimental and can be disabled if it causes issues.* Reduces the total number of queries issued and speeds up profiling by dynamically combining SQL queries where possible.",
"default": true,
"type": "boolean"
},
"catch_exceptions": {
"title": "Catch Exceptions",
"default": true,
"type": "boolean"
},
"partition_profiling_enabled": {
"title": "Partition Profiling Enabled",
"description": "Whether to profile partitioned tables. Only BigQuery and Aws Athena supports this. If enabled, latest partition data is used for profiling.",
"default": true,
"type": "boolean"
},
"partition_datetime": {
"title": "Partition Datetime",
"description": "If specified, profile only the partition which matches this datetime. If not specified, profile the latest partition. Only Bigquery supports this.",
"type": "string",
"format": "date-time"
},
"use_sampling": {
"title": "Use Sampling",
"description": "Whether to profile column level stats on sample of table. Only BigQuery and Snowflake support this. If enabled, profiling is done on rows sampled from table. Sampling is not done for smaller tables. ",
"default": true,
"type": "boolean"
},
"sample_size": {
"title": "Sample Size",
"description": "Number of rows to be sampled from table for column level profiling.Applicable only if `use_sampling` is set to True.",
"default": 10000,
"type": "integer"
},
"profile_external_tables": {
"title": "Profile External Tables",
"description": "Whether to profile external tables. Only Snowflake and Redshift supports this.",
"default": false,
"type": "boolean"
},
"tags_to_ignore_sampling": {
"title": "Tags To Ignore Sampling",
"description": "Fixed list of tags to ignore sampling. If not specified, tables will be sampled based on `use_sampling`.",
"type": "array",
"items": {
"type": "string"
}
},
"method": {
"title": "Method",
"default": "ge",
"enum": [
"ge"
],
"type": "string"
},
"warehouse_id": {
"title": "Warehouse Id",
"description": "SQL Warehouse id, for running profiling queries.",
"type": "string"
},
"pattern": {
"title": "Pattern",
"description": "Regex patterns to filter tables for profiling during ingestion. Specify regex to match the `catalog.schema.table` format. Note that only tables allowed by the `table_pattern` will be considered.",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"max_wait_secs": {
"title": "Max Wait Secs",
"description": "Maximum time to wait for a table to be profiled.",
"type": "integer"
}
},
"additionalProperties": false
},
"UnityCatalogAnalyzeProfilerConfig": {
"title": "UnityCatalogAnalyzeProfilerConfig",
"type": "object",
"properties": {
"method": {
"title": "Method",
"default": "analyze",
"enum": [
"analyze"
],
"type": "string"
},
"warehouse_id": {
"title": "Warehouse Id",
"description": "SQL Warehouse id, for running profiling queries.",
"type": "string"
},
"pattern": {
"title": "Pattern",
"description": "Regex patterns to filter tables for profiling during ingestion. Specify regex to match the `catalog.schema.table` format. Note that only tables allowed by the `table_pattern` will be considered.",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"enabled": {
"title": "Enabled",
"description": "Whether profiling should be done.",
"default": false,
"type": "boolean"
},
"operation_config": {
"title": "Operation Config",
"description": "Experimental feature. To specify operation configs.",
"allOf": [
{
"$ref": "#/definitions/OperationConfig"
}
]
},
"profile_table_level_only": {
"title": "Profile Table Level Only",
"description": "Whether to perform profiling at table-level only or include column-level profiling as well.",
"default": false,
"type": "boolean"
},
"call_analyze": {
"title": "Call Analyze",
"description": "Whether to call ANALYZE TABLE as part of profile ingestion.If false, will ingest the results of the most recent ANALYZE TABLE call, if any.",
"default": true,
"type": "boolean"
},
"max_wait_secs": {
"title": "Max Wait Secs",
"description": "Maximum time to wait for an ANALYZE TABLE query to complete.",
"default": 3600,
"type": "integer"
},
"max_workers": {
"title": "Max Workers",
"description": "Number of worker threads to use for profiling. Set to 1 to disable.",
"default": 20,
"type": "integer"
}
},
"additionalProperties": false
},
"DeltaLakeDetails": {
"title": "DeltaLakeDetails",
"type": "object",
"properties": {
"platform_instance_name": {
"title": "Platform Instance Name",
"description": "Delta-lake paltform instance name",
"type": "string"
},
"env": {
"title": "Env",
"description": "Delta-lake environment",
"default": "PROD",
"type": "string"
}
},
"additionalProperties": false
}
}
}
Advanced
Multiple Databricks Workspaces
If you have multiple databricks workspaces that point to the same Unity Catalog metastore, our suggestion is to use separate recipes for ingesting the workspace-specific Hive Metastore catalog and Unity Catalog metastore's information schema.
To ingest Hive metastore information schema
- Setup one ingestion recipe per workspace
- Use platform instance equivalent to workspace name
- Ingest only hive_metastore catalog in the recipe using config
catalogs: ["hive_metastore"]
To ingest Unity Catalog information schema
- Disable hive metastore catalog ingestion in the recipe using config
include_hive_metastore: False - Ideally, just ingest from one workspace
- To ingest from both workspaces (e.g. if each workspace has different permissions and therefore restricted view of the UC metastore):
- Use same platform instance for all workspaces using same UC metastore
- Ingest usage from only one workspace (you lose usage from other workspace)
- Use filters to only ingest each catalog once, but shouldn’t be necessary
Troubleshooting
No data lineage captured or missing lineage
Check that you meet the Unity Catalog lineage requirements.
Also check the Unity Catalog limitations to make sure that lineage would be expected to exist in this case.
Lineage extraction is too slow
Currently, there is no way to get table or column lineage in bulk from the Databricks Unity Catalog REST api. Table lineage calls require one API call per table, and column lineage calls require one API call per column. If you find metadata extraction taking too long, you can turn off column level lineage extraction via the include_column_lineage config flag.
Code Coordinates
- Class Name:
datahub.ingestion.source.unity.source.UnityCatalogSource - Browse on GitHub
Questions
If you've got any questions on configuring ingestion for Databricks, feel free to ping us on our Slack.